Z.16 Simulations
- Configuring Simulation
- Configuring Resources for Simulation
- Workload Event Format
- Interactive Simulation Tutorial
Simulations allow organizations to evaluate many scenarios that could not be effectively evaluated in the real world. In particular, these evaluations may be impossible due to time constraints, budgetary or man-power limitations, hardware availability, or may even be impossible due to policy issues.
|
|
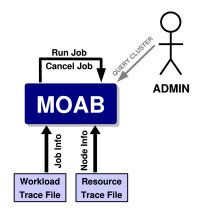
Image Z-2: Moab simulation setup (information retrieved from a workload trace file) |
|
In such cases, simulation can help answer questions in countless scenarios and provide information such as the following:
- What is the impact of additional hardware on cluster utilization?
- What delays to key projects can be expected with the addition of new users?
- How will new prioritization weights alter cycle distribution among existing workload?
- What total loss of compute resources will result from introducing a maintenance downtime?
- Are the benefits of cycle stealing from non-dedicated desktop systems worth the effort?
- How much will anticipated grid workload delay the average wait time of local jobs?
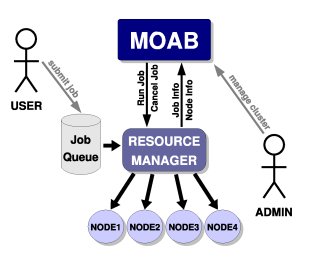
Simulation Architecture and Environment
In a production environment, Moab engages with the real-world ecosystem, interacting with users and updating workload and resource information from a resource manager such as TORQUE. This resource manager holds authoritative information regarding the configuration, load, health, and workload on the compute nodes which make up the cluster. This information is updated periodically as jobs start and complete. Users and admins interact with the system, submitting new jobs and modifying policies and reservations respectively.
For a simulation to behave in a manner which closely tracks the real world, each of these environmental factors must be modeled. Specifically, the following factors must be supported:
- Workload
- Resources
- Policies
- Users
- Time
Workload. In a simulation, there is no live resource manager providing job information so Moab must obtain this information from an alternate source. For this, Moab uses a workload trace file, a file which contains information about which jobs the simulation should run including low-level details such as job id, job credentials, resource requirements, submit time, execution time, dependencies, etc. Moab simulation pulls workload from this trace file and introduces it into the system according to various policies.
Resources. Like workload, in a simulation, there is no live resource manager providing node state information. In a simulation, this information must be specified using a static native resource manager. This native resource manager loads the cluster's initial state from a specified static text file and then Moab continues to update this initial data over time. As workload is scheduled, Moab applies its knowledge of the workload to adjust node state, node workload, node load, etc.
Policies. Moab simulation loads policies in exactly the same manner as a production instance. This means a simulation can use an production Moab config file as a starting point, with changes only to specific policies and configurations which are being tested.
Users. Modeling users is one of the core challenges of simulation. To do this, Moab uses simulation job submission policies which will be described in more detail in later sections.
Time. Simulations often evaluate days, weeks or months of workload data to obtain statistically meaningful results. Consequently, the simulation must provide an internal simulation clock which can be sped up in order to deliver results in a more timely manner. Moab simulation allows control over this clock allowing the clock to be started, stopped, stepped forward, etc.
Simulation Execution
While production instances of Moab can only be run on certain nodes and require access to services such as TORQUE or the Moab Accounting Manager, a Moab simulation can be completely self contained. This allows it to be run on the same node as the production instance or run on a different server, or even run on a laptop. All that is required is an appropriate Moab home directory structure (etc, log, stats, etc), the Moab binaries, the workload and resource trace information and the license file.
NOTE: If running a simulation on the same node as the Moab production instance, the simulation MUST run in a different home directory otherwise their will be conflicts with checkpoint files, lock files, logs, and statistics
NOTE: If running a simulation on the same node as the Moab production instance, the simulation MUST be configured to use a different port to avoid conflicts with client commands attempting to connect with the production scheduler