Chapter 24 About Data Staging
Sometimes you might need a job to process data that resides at another site. With the proper configuration, you can submit your job with the requirement that it copies data from the external site to yours and, if needed, copy the job's resulting data out to the external site for its owner to use. Data staging is an out-of-band method of moving data without reserving compute nodes or other resources for it.
In the example below, which will appear throughout the chapter, a university researcher needs the results of tests done at a hospital to run his job. User davidharris on the student server of the university submits a job called
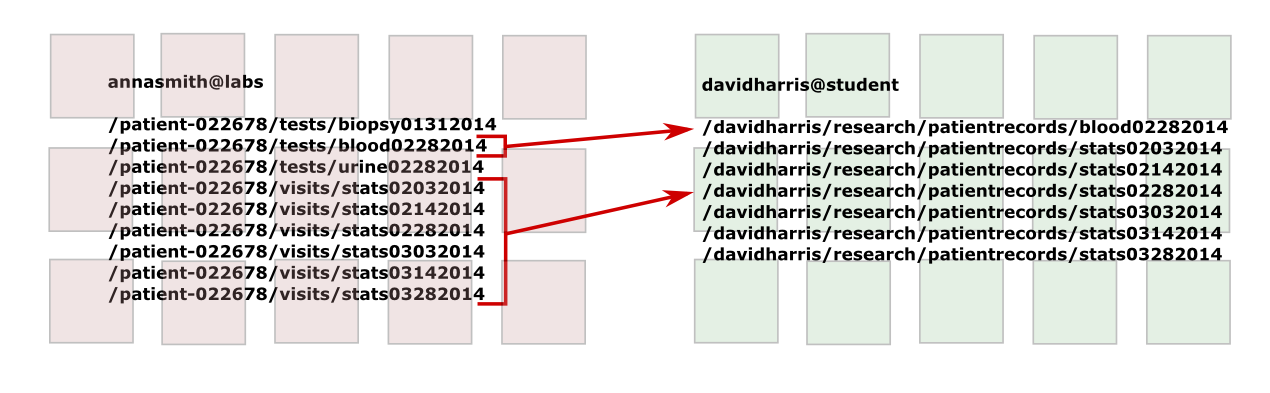
|
|
Click to enlarge |
Moab currently supports the following data staging use cases: 1) Staging data to or from a shared file system, 2) Staging data to or from local node storage on a single compute node, and 3) Staging data to or from a shared file system on an unspecified cluster – resolved at job migration – in a grid configuration.
Before you can submit data staging jobs, you must configure certain generic metrics in your partitions, job templates, and the data staging submit filter for data staging scheduling, throttling, and policies.
Moab uses Linux file transfer utilities to stage the data and includes data staging reference scripts that support the scp and rsync Linux file transfer utilities. The scripts will work for standard installations, but you can customize the script to support data staging to and from an external staging server, the Moab server itself, or a local compute node, depending on your implementation. You can also customize your own script for other file transfer utilities, such as Aspera.
Once you configure your system to support data staging, you can begin creating data staging jobs by attaching the --stagein, --stageinfile, --stageinsize, --stageout, --stageoutfile, and --stageoutsize options to your msub commands. See Staging data for more information.
The following topics describe how to stage data in different Moab environments.
- Configuring the SSH keys for the Data Staging Transfer Script
- Configuring Data Staging
- Configuring the $CLUSTERHOST variable
- Staging Data to or from a Shared File System
- Staging Data to or from a Shared File System in a Grid
- Staging Data to or from a Compute Node
- Configuring Data Staging with Advanced Options
The following topics contain detailed information that you can use as reference material for data staging
Related Topics