Chapter 1: About high availability
High availability (HA) allows Moab to run on two different machines: a primary and secondary server. The configuration method to achieve this behavior takes advantage of a networked file system to configure two Moab servers with only one operating at a time.

If you use a shared file system for HA and Moab is configured to use a database, Moab must be an ODBC build, not SQLite.
On startup, each Moab server in the HA pair reads configuration files from the shared common area and checks the last modification date of a file configured using the HALOCKFILE attribute of SCHEDCFG. If the file has not been modified recently, the server assumes the role of master and begins touching the file every few seconds. If the file has been modified recently, the server assumes another entity is serving as master; it reverts to a standby mode. It repeats its check of the last modification date periodically. If the master server crashes, the last modification date becomes stale and the standby server activates.
|
Image 1-1: Moab and TORQUE using HA on paired head nodes. |
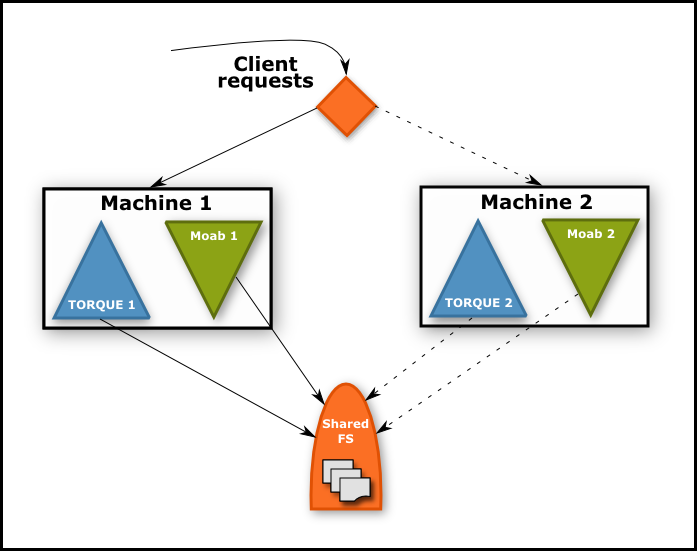
|
|
Click to enlarge |
As Moab uses timestamping in the lock file to implement high availability, the clocks on both servers require synchronization; both machines in the cluster must be synchronized to the same time server.
Moab high availability and TORQUE high availability operate independently of each other. If a job is submitted with msub and the primary Moab server is down, msub tries to connect to the fallback Moab server. Once the job is given to TORQUE, if TORQUE can't connect to the primary pbs_server, it tries to connect to the fallback pbs_server. For example:
A job is submitted with msub, but Moab is down on server01, so msub contacts Moab running on server02.
A job is submitted with msub and Moab hands it off to TORQUE, but pbs_server is down on server01, so qsub contacts pbs_server running on server02.
© 2012 Adaptive Computing 