How It Works
Overview
Adaptive Computing’s HPC Cloud On-Demand Data Center™ (ODDC) is a scalable cloud systems
management solution that gives organizations the ability to leverage public Cloud Service
Provider (CSP) resources, without vendor lock-in to any single CSP.
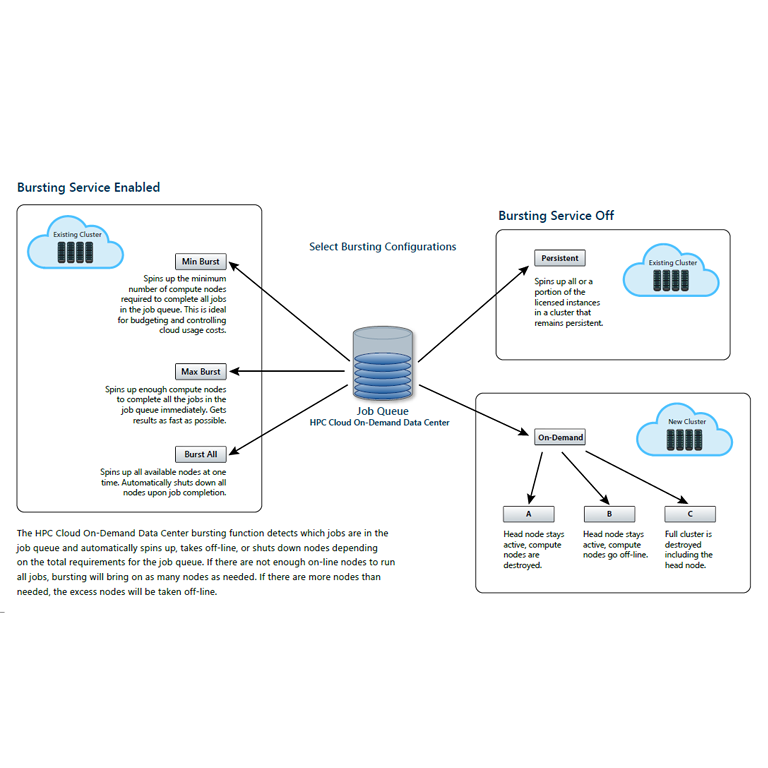
The HPC Cloud On-Demand Data Center is used to spin up temporary or persistent data
center infrastructure resources quickly, inexpensively, and on-demand. This enterprise-grade
solution can be used to automatically deploy and build clusters in the Cloud, automatically run
applications on those clusters, and then terminate the cloud resources, assuring that you only
pay for what is being used.
The HPC Cloud On-Demand Data Center provides ways to run HPC workloads in the Cloud as an abstraction layer on top of CSP management consoles. Deploying cloud-hosted resources on any of the major Cloud Service Providers becomes much easier than working directly through a CSP console because cloud access is preconfigured and built into the user-friendly interface GUI (and CLI) of the HPC Cloud On-Demand Data Center.
This preconfigured CSP access eliminates the complexities of running workloads in the Cloud for users without cloud expertise. OCI, AWS, Google Cloud, Azure, and OTC are available through the intuitive interface, making HPC in the Cloud available to non-technical users.