



Appendix Q: Moab in the Data Center
Moab provides support for today's data centers, a hybrid of traditional data center workflows and dynamic, service-oriented processes. The sections below describe how a data center can best take advantage of Moab's capabilities.
- Q.1 Introduction
- Q.2 Installation
- Q.3 Transitioning Workflow
- Q.3.1 Defining the Workflow
- Q.3.2 Inventory of Resources
- Q.3.2.1 Moab Node Structure
- Q.3.2.2 Defining Nodes in Moab
- Q.3.2.3 Mapping Workflow Requirements to Resources
- Q.3.3 Defining Job Groups
- Q.3.4 Setting the Schedule
- Q.3.4.1 Determining Scheduling Requirements
- Q.3.4.2 Creating Standing Reservations
- Q.3.4.3 Submitting a Job to a Standing Reservation
- Q.3.5 Workflow Dependencies
- Q.4 Dynamic Workload
- Q.5 Supporting SLAs and Other Commitments
- Q.CS Case Studies
Q.1 Introduction
![]() Note: The Intersection of HPC & the Data Center is a video tutorial of a session offered at Moab Con that offers further details for understanding High Performance Computing (HPC) and data centers.
Note: The Intersection of HPC & the Data Center is a video tutorial of a session offered at Moab Con that offers further details for understanding High Performance Computing (HPC) and data centers.
![]() Note: Adaptive Data Center is a video tutorial that offers further details for understanding adaptive data centers.
Note: Adaptive Data Center is a video tutorial that offers further details for understanding adaptive data centers.
Welcome to Moab in the Data Center. Widely used in the HPC sector, Moab provides many unique solutions to the problems faced by today's data center administrators on a daily basis. In addition to supporting the traditional data center workload model, Moab leverages more than ten years of experience in HPC to provide the dynamic scheduling needed in today's data center where Web services and other ad hoc, service-oriented processes are becoming more prevalent. This document outlines the easy process of evolving to this new paradigm—a world where the data center and service-oriented computing intertwine.
Q.1.1 The Traditional Data Center
Data centers often view compute resources differently than traditional HPC centers. The flow of data and computation within many data centers is fairly static in nature, with each new day being very similar to the last. Workload may vary throughout the day and week to match standard business hours. Month-end, quarter-end and year-end create predictable spikes in work. So, while workload may vacillate, there is a predictable ebb and flow.
Table 1: Data Center vs. HPC Comparison
| Data Center | HPC |
|---|---|
|
Data-Centric Jobs Standardized/Static Workload Short Jobs Many Dependencies Specific Resources for Specific Jobs |
Compute-Centric Jobs Dynamic Workload Long Jobs Few Dependencies Non-Specific Resources for All Jobs |
Table 1 is an overly-simplified, overly-generalized view of the differences between the traditional Data Centers and HPC models. However, in most cases, this description is fairly accurate. However, this is changing within the industry. Recently, many data centers have begun to offer additional, on-demand, service-oriented products to their clients, such as Web services support and database searches, thus creating a hybrid model somewhere between traditional data center and traditional HPC.
The infusion of these dynamic jobs into the data center have put new demands on the system and its administrators. The new dynamic jobs must be handled in such a way as to protect the core business processes, while still providing the contracted dynamic services to clients and meeting SLAs. The sophistication required in the management software has stretched many current data center solutions to or past the breaking point, prompting administrators to search for new solutions.
Q.1.2 Moab Utility/Hosting Suite
Moab Utility/Hosting Suite is a professional cluster workload management solution that integrates the scheduling, managing, monitoring and reporting of cluster workloads. Moab Utility/Hosting Suite simplifies and unifies management across one or multiple hardware, operating system, storage, network, license and resource manager environments. Its task-oriented management and the industry's most flexible policy engine ensure service levels are delivered and workload is processed faster. This enables organizations to accomplish more work resulting in improved cluster ROI.
The power is in the software. Moab will run on today's common hardware solutions. There isn't a need to replace or make changes to the data center's underlying architecture, in most cases. Moab can interface with many different types of resource management software, including in-house solutions, to learn about its environment. With the gathered information, Moab dynamically schedules resources and plans for the future. So, the system is optimized not only for the moment, but also for the future.
With its state-of-the-art scheduling engine, Moab can empower today's data centers to handle tomorrow's workload. Relying on technology and techniques developed over the last decade, Moab's three-dimensional scheduling algorithms provide an environment where static workloads and dynamic jobs can peacefully coexist, each receiving the proper resources at the proper time. The fully-customizable policy control mechanism allows data centers to enforce any needed policy, whether technical, financial, or political. Both GUI and CLI tools exist for administration.
Q.2 Installation
The installation process for a Moab system is straightforward. However, it is accomplished in two separate steps: Moab and the resource managers.
Q.2.1 Moab
In most cases, Moab is distributed as a binary tarball. Builds are readily available for all major architectures and operating systems. These packages are available to those with a valid full or evaluation license.
Example 1: Moab install process
> tar xvzf moab-5.1.0-i386-libtorque-p2.tar.gz > ./configure > make > make install
Example 1 shows the commands to do a basic installation from the command line for Moab. In this case, the install package for Moab 5.1.0 (patch 2) needs to be in the current directory.
Example 2: Default contents of /opt/moab
drwxr-xr-x 2 root root 4096 2010-04-02 12:24 bin drwxr-xr-x 2 root root 4096 2010-04-02 12:24 etc drwxr-xr-x 2 root root 4096 2010-04-02 12:24 include drwxr-xr-x 2 root root 4096 2010-04-02 12:26 log drwxr-xr-x 2 root root 4096 2010-04-02 12:24 sbin drwxrwxrwt 2 root root 4096 2010-04-02 12:42 spool drwxr-xr-x 2 root root 4096 2010-04-02 12:26 stats drwxr-xr-x 2 root root 4096 2010-04-02 12:24 traces
By default, Moab installs to the /opt/moab directory. Example 2 shows a sample ls -l output in /opt/moab.
The binary installation creates a default moab.cfg file in the etc/ folder. This file contains the global configuration for Moab that is loaded each time Moab is started. The definitions for users, groups, nodes, resource manager, quality of services and standing reservations are placed in this file. While there are many settings for Moab, only a few will be discussed here. The default moab.cfg that is provided with a binary installation is very simple. The installation process defines several important default values, but the majority of configuration needs to be done by the administrator, either through directly editing the file or using one of the provided administrative tools such as Moab Cluster Manager (MCM).
Example 3: Default moab.cfg file
SCHEDCFG[Moab] SERVER=allbe:42559 ADMINCFG[1] USERS=root,root RMCFG[base] TYPE=PBS
Example 3 shows the default moab.cfg file sans-comments. The first line defines a new scheduler named Moab. In this case, it is located on a host named allbe and listening on port 42559 for client commands. These values are added by the installation process, and should be kept in most cases.
The second line, however, requires some editing by the administrator. This line defines what users on the system have Level 1 Administrative rights. These are users who have global access to information and unlimited control over scheduling operations in Moab. There are five default administrative levels defined by Moab, each of which is fully customizable. In Example 3, this line needs to be updated. The second root entry needs to be changed to the username of the administrator(s) of the system. The first root entry needs to remain, as Moab needs to run as root in order to submit jobs to the resource managers as the original owner.
The final line in this example is the configuration for the default resource manager. This particular binary distribution is for the TORQUE resource manager. Because TORQUE follows the PBS style of job handling, the resource manager is given a type of PBS. To differentiate it from other resource managers that may be added in the future, it is also given the name base. Resource managers will be discussed in the next section.
This constitutes the basic installation of Moab. Many additional parameters can be added to the moab.cfg file in order to fully adapt Moab to the needs of your particular data center. A more detailed installation guide is available.
Q.2.2 Resource Managers
The job of Moab is to schedule resources. In fact, Moab views the world as a vast collection of resources that can be scheduled for different purposes. It is not, however, responsible for the direct manipulation of these resources. Instead, Moab relies on resource managers to handle the fine details in this area. Moab makes decisions and sends the necessary commands to the resource managers, which execute the commands and return state information back to Moab. This decoupling of Moab from the actual resources allows Moab to support all possible resource types, as it doesn't need specific knowledge about the resources, only a knowledge of how to communicate with the resource manager.
Moab natively supports a wide range of resource managers. For several of these, Moab interacts directly with the resource manager's API. These include TORQUE, LSF and PBS. For these resource managers, a specific binary build is required to take advantage of the API calls. For other resource managers, Moab supports a generic interface known as the Native Interface. This allows interfaces to be built for any given type of resource manager, including those developed in-house. Cluster Resources supplies a large number of pre-built interfaces for the most common resource managers. They also provide information on building custom interfaces, as well as contract services for specialized development.
The setup of each individual resource manager is beyond the scope of this document. However, most resource managers come with ample instructions and/or wizards to aid in their installation. TORQUE, an open-source resource manager under the auspice of Cluster Resources, has a documentation WIKI. This includes instructions on installing and testing TORQUE. Please note that special SSH or NFS configuration may also be required in order to get data staging to work correctly.
Once the resource manager(s) are installed and configured, the moab.cfg file will need to be updated if new or different resource managers have been added. Valid resource manager types include: LL, LSF, PBS, SGE, SSS and WIKI. General information on resource managers is found in Chapter 13. Integration guides for specific resource managers are also available.
Q.2.3 Checking the Installation
Once Moab and the resource managers have been installed, there are several steps that should be followed to check the installation.
- Start the Resource Manager — See resource manager's documentation
- Start Moab — Run Moab from the command line as root
- Run Resource Manager Tests — See resource manager's documentation
- Check Moab Install — See below
 |
> moabd is a safe and recommended method of starting Moab if things are not installed in their default locations. |
Checking the Moab installation is a fairly straightforward process. The first test is to run the program showq. This displays the Moab queue information. Example 4 shows a sample output from showq. In this case, the system shown is a single node, which is a 64-processor SMP machine. Also, there are currently no jobs running or queued. So, there are no active processors or nodes.
Example 4: Sample showq
active jobs------------------------
JOBID USERNAME STATE PROC REMAINING STARTTIME
0 active jobs 0 of 64 processors in use by local jobs (0.00%)
0 of 1 nodes active (0.00%)
eligible jobs----------------------
JOBID USERNAME STATE PROC WCLIMIT QUEUETIME
0 eligible jobs
blocked jobs-----------------------
JOBID USERNAME STATE PROC WCLIMIT QUEUETIME
0 blocked jobs
Total jobs: 0
The important thing to look for at this point is the total number of processors and nodes. If either the total number of processors or nodes is 0, there is a problem. Generally, this is would be caused by a communication problem between Moab and the resource manager, assuming the resource manager is configured correctly and actively communicating with each of the nodes for which it has responsibility.
The current state of the communication links between Moab and the resource managers can be viewed using the mdiag -R -v command. This gives a verbose listing of the resource managers configured in Moab, including current state, statistics, and any error messages.
Example 5: Sample mdiag -R -v output
diagnosing resource managers RM[base] State: Active Type: PBS ResourceType: COMPUTE Version: '2.2.0' Objects Reported: Nodes=1 (64 procs) Jobs=0 Flags: executionServer,noTaskOrdering Partition: base Event Management: EPORT=15004 (last event: 00:01:46) Note: SSS protocol enabled Submit Command: /usr/local/bin/qsub DefaultClass: batch Total Jobs Started: 3 RM Performance: AvgTime=0.00s MaxTime=1.45s (8140 samples) RM Languages: PBS RM Sub-Languages: - RM[internal] State: --- Type: SSS Max Failure Per Iteration: 0 JobCounter: 5 Version: 'SSS4.0' Flags: localQueue Event Management: (event interface disabled) RM Performance: AvgTime=0.00s MaxTime=0.00s (5418 samples) RM Languages: - RM Sub-Languages: - Note: use 'mrmctl -f messages' to clear stats/failures
In Example 5, two different resource managers are listed: base and internal. The base resource manager is the TORQUE resource manager that was defined in Example 3. It is currently showing that it is healthy and there are no communication problems. The internal resource manager is used internally by Moab for a number of procedures. If there were any problems with either resource manager, messages would be displayed here. Where possible, error messages include suggested fixes for the noted problem.
Another command that can be very helpful when testing Moab is mdiag -C, which does a format check on the moab.cfg file to ensure that each line has a recognizable format.
Example 6: Sample mdiag -C output
INFO: line #15 is valid: 'SCHEDCFG[Moab] SERVER=allbe:42559' INFO: line #16 is valid: 'ADMINCFG[1] USERS=root,guest2' INFO: line #23 is valid: 'RMCFG[base] TYPE=PBS'
The state of individual nodes can be checked using the mdiag -n command. Verbose reporting of the same information is available through mdiag -n -v.
Example 7: Sample mdiag -n output
compute node summary Name State Procs Memory Opsys allbe Idle 64:64 1010:1010 linux ----- --- 64:64 1010:1010 ----- Total Nodes: 1 (Active: 0 Idle: 1 Down: 0)
In this case (Example 7), there is only a single compute node, allbe. This node has 64 processors and is currently idle, meaning it is ready to run jobs, but is not currently doing anything. If a job or jobs had been running on the node, the node would be noted as active, and the Procs and Memory column would indicate not only the total number configured, but also the number currently available.
The next test is to run a simple job using Moab and the configured resource manager. This can be done either through the command line or an administrative tool like MCM. This document will show how this is done utilizing the command line.
Example 8: Simple sleep job
> echo "sleep 60" | msub
The command in Example 8 submits a job that simply sleeps for 60 seconds and returns. While this may appear to have little or no point, it allows for the testing of the job submission procedures. As the root user is not allowed to submit jobs, this command needs to be run as a different user. When this command is run successfully, it will return the Job ID of the new job. The job should also appear in showq as running (assuming the queue was empty), seen in Example 9.
Example 9: Sample showq output with running job
active jobs------------------------
JOBID USERNAME STATE PROC REMAINING STARTTIME
40277 user1 Running 1 00:59:59 Tue Apr 3 11:23:33
1 active job 1 of 64 processors in use by local jobs (1.56%)
1 of 1 nodes active (100.00%)
eligible jobs----------------------
JOBID USERNAME STATE PROC WCLIMIT QUEUETIME
0 eligible jobs
blocked jobs-----------------------
JOBID USERNAME STATE PROC WCLIMIT QUEUETIME
0 blocked jobs
Total jobs: 1
If showq indicated a problem with the job, such as it being blocked, additional information regarding the job can be gained using checkjob job_id. Example 10 shows some sample output of this command. More verbose information can be gathered using checkjob -v job_id.
Example 10: Sample checkjob output
job 40277 AName: STDIN State: Running Creds: user:user1 group:user1 class:batch WallTime: 00:01:32 of 1:00:00 SubmitTime: Tue Apr 3 11:23:32 (Time Queued Total: 00:00:01 Eligible: 00:00:01) StartTime: Tue Apr 3 11:23:33 Total Requested Tasks: 1 Req[0] TaskCount: 1 Partition: base Memory >= 0 Disk >= 0 Swap >= 0 Opsys: --- Arch: --- Features: --- NodesRequested: 1 Allocated Nodes: [allbe:1] IWD: /opt/moab Executable: /opt/moab/spool/moab.job.A6wPSf StartCount: 1 Partition Mask: [base] Flags: RESTARTABLE,GLOBALQUEUE Attr: checkpoint StartPriority: 1 Reservation '40277' (-00:01:47 -> 00:58:13 Duration: 1:00:00)
If jobs can be submitted and run properly, the system is configured for basic use. As the transition to a Moab-centric system continues, additional items will be placed in the moab.cfg file. After each change to the moab.cfg file, it is necessary to restart Moab for the changes to take effect. This simple process is shown in Example 11.
Example 11: Restarting Moab
> mschedctl -R
Other commands administrators will find useful are shown below.
Example 12: Shutting down Moab
> mschedctl -k
Example 13: Show server statistics
> mdiag -S
Example 14: Show completed jobs (last 5 minutes)
> showq -c
Q.3 Transitioning Workflow
With its advanced scheduling capabilities, Moab can easily handle all the scheduling needs of data centers. Core resources can be protected while still optimizing the workload to get the highest efficiency, productivity, and ROI possible. Almost all of the Data Center's existing structure and architecture is maintained. Additional steps must be made to describe the workflow and related policies to Moab, which will then intelligently schedule the resources to meet the organization's goals. Transitioning to Moab follows some important steps:
- Determine existing business processes and related resources and policies.
- For each business process, determine and chart the process, making sure to include all required resources, start times, deadlines, internal dependencies, external dependencies, decision points and critical paths.
- Where possible, divide processes into functional groups that represent parts of the overall process that should be considered atomic or closely related.
- Translate functional groups and larger processes into programmatic units that will be scheduled by Moab.
- Build control infrastructure to manage programmatic units to form processes.
- Identify on-demand services and related resources and policies.
- Implement system-wide policies to support static and dynamic workloads.
Most data centers have already done many, if not all, of these steps in the normal management of their system. The other major part of the transition is the taking of these steps and applying them to Moab to gain the desired results. The remainder of this section covers approaches and techniques you can use to accomplish these tasks.
Q.3.1 Defining the Workflow
Workflow is the flow of data and processing through a dynamic series of tasks controlled by internal and external dependencies to accomplish a larger business process. As one begins the transition to Moab, it is important to have a clear understanding of the needed workflow and the underlying business processes it supports. Figure 1 shows a simple workflow diagram with multiple processing paths and external data dependencies.
Figure 1: Sample workflow diagram
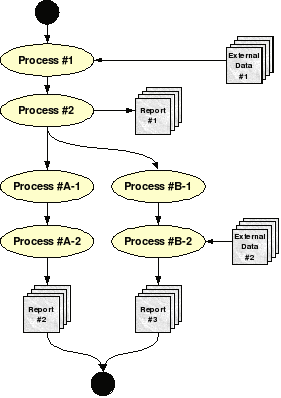
It is important to create one or more diagrams such as this to document the workflow through one's system. This diagram provides a visual representation of the system, which clearly shows how data flows through the processing jobs, as well as all dependencies.
In this diagram, External Data is a type of external dependency. An external dependency is a dependency that is fulfilled external to the workflow (and maybe even the system). It is not uncommon for external dependencies to be fulfilled by processes completely external to the cluster on which Moab is running. Consequently, it is very important to clearly identify such dependencies, as special steps must be taken for Moab to be alerted when these dependencies are fulfilled.
Once all of the business processes have been succinctly described and diagrammed, it is possible to continue with the conversion process. The next step is to inventory the available resources. It is also at this point that the pairing of resources and workflow tasks is done.
Q.3.2 Inventory of Resources
At the most basic level, Moab views the world as a group of resources onto which reservations are placed, managed, and optimized. It is aware of a large number of resource types, including a customizable generic resource that can be used to meet the needs of even the most complex data center or HPC center. Resources can be defined as software licenses, database connections, network bandwidth, specialized test equipment or even office space. However, the most common resource is a compute node.
Q.3.2.1 Moab Node Structure
During the transition to Moab, the administrator must make an inventory of all relevant resources and then describe them to Moab. Because the approach with Moab is different than the traditional data center paradigm, this section will focus on the configuration of compute nodes. Figure 2 shows a basic view of Moab node structure.
Figure 2: Moab node structure
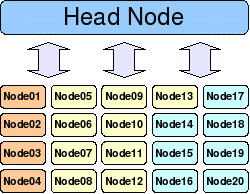
All clusters have a head node, which is where Moab resides. It is from this node that all compute jobs are farmed out to the compute nodes. These compute nodes need not be homogeneous. Figure 2 depicts a heterogeneous cluster where the different colors represent different compute node types (architecture, processors, memory, software, and so forth).
Q.3.2.2 Defining Nodes in Moab
Moab interacts with the nodes through one or more resource managers. Common resource managers include TORQUE, SLURM, LSF, LoadLeveler and PBS. In general, the resource manager will provide Moab with most of the basic information about each node for which it has responsibility. This basic information includes number of processors, memory, disk space, swap space and current usage statistics. In addition to the information provided by the resource manager, the administrator can specify additional node information in the moab.cfg file. Following is an extract from the moab.cfg file section on nodes. Because this is a simple example, only a few node attributes are shown. However, a large number of possible attributes, including customizable features are available. Additional node configuration documentation is available.
Example 15: Sample node configuration
NODECFG[Node01] ARCH=ppc OS=osx NODECFG[Node02] ARCH=ppc OS=osx NODECFG[Node07] ARCH=i386 OS=suse10 NODECFG[Node08] ARCH=i386 OS=suse10 NODECFG[Node18] ARCH=opteron OS=centos CHARGERATE=2.0 NODECFG[Node19] ARCH=opteron OS=centos CHARGERATE=2.0
In Example 15, we see six nodes. The architecture and operating system is specified on all of these. However, the administrator has enabled a double charge rate for jobs that are launched on the last two. This is used for accounting purposes.
Node attributes are considered when a job is scheduled by Moab. For example, if a specific architecture is requested, the job will only be scheduled on those nodes that have the required architecture.
Q.3.2.3 Mapping Workflow Requirements to Resources
Once relevant resources have been configured in Moab, it is necessary to map the different stages of the workflow to the appropriate resources. Each compute stage in the workflow diagrams needs to be mapped to one or more required resource. In some cases, specifying "No Preference" is also valid, meaning it does not matter what resources are used for the computation. This step also provides the opportunity to review the workflow diagrams to ensure that all required resources have an appropriate mapping in Moab.
Q.3.3 Defining Job Groups
With the completed workflow diagrams, it is possible to identify functional groups. Functional groups can be demarcated along many different lines. The most important consideration is whether the jobs will need to share information amongst themselves or represent internal dependencies. These functional groups are known as job groups. Job groups share a common name space wherein variables can be created, allowing for communication among the different processes.
Often job groups will be defined along business process lines. In addition, subgroups can also be defined to allow the workflow to be viewed in more manageable sections.
Q.3.4 Setting the Schedule
As was previously mentioned, Moab views the world as a set of resources that can be scheduled. Scheduling of resources is accomplished by creating a reservation. Some reservations are created automatically, such as when a job is scheduled for launch. Other reservations can be created manually by the administrator. Manual reservations can either be static, meaning they are part of Moab's configuration (moab.cfg) or ad hoc, created as needed via the command line or the MCM tool.
Q.3.4.1 Determining Scheduling Requirements
Within any data center, some jobs are high priority, while others are low priority. It is necessary to make sure resources are available to the high priority jobs, especially when these jobs are part of an SLA or part of a time-critical business process. Moab supports a number of configuration options and parameters to support these scheduling goals.
In this section we will look at the situation where part of the cluster needs to be reserved for certain processes during the day. Figure 3 shows a ten node cluster and its daily scheduling requirements. There are four service areas that must have sole access to their associated nodes during specific times of the day. All other jobs are allowed to float freely among the free processors. This example is typical of many data centers where workload is dependent on the time of day or day of week.
Figure 3: Daily standing reservations
| Node01 | Node02 | Node03 | Node04 | Node05 | Node06 | Node07 | Node08 | Node09 | Node10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 12:00 AM | ||||||||||
| 1:00 AM | ||||||||||
| 2:00 AM | ||||||||||
| 3:00 AM | ||||||||||
| 4:00 AM | ||||||||||
| 5:00 AM | ||||||||||
| 6:00 AM | ||||||||||
| 7:00 AM | ||||||||||
| 8:00 AM | ||||||||||
| 9:00 AM | ||||||||||
| 10:00 AM | ||||||||||
| 11:00 AM | ||||||||||
| 12:00 PM | ||||||||||
| 1:00 PM | ||||||||||
| 2:00 PM | ||||||||||
| 3:00 PM | ||||||||||
| 4:00 PM | ||||||||||
| 5:00 PM | ||||||||||
| 6:00 PM | ||||||||||
| 7:00 PM | ||||||||||
| 8:00 PM | ||||||||||
| 9:00 PM | ||||||||||
| 10:00 PM | ||||||||||
| 11:00 PM | ||||||||||
| Nightly Batch Processing | Web Services | |||||||||
| Daily Business Processes | Contracted Service Access | |||||||||
It is important to have a clear understanding of what jobs require hard reservations such as the ones shown here and those that are more forgiving. A particular strength of Moab is its ability to schedule in a dynamic environment while still being able to support many scheduling goals. The standing reservation approach limits the ability for Moab to dynamically schedule, as it limits what can be scheduled on certain nodes during certain times. Cycles lost in a standing reservation because the jobs for which the reservation was made do not use the entire time block cannot be reclaimed by Moab. However, standing reservations are a powerful way to guarantee resources for mission-critical processes and jobs.
Q.3.4.2 Creating Standing Reservations
If it is determined that standing reservations are appropriate, they must be created in Moab. Standing reservations are created in the moab.cfg file. However, before the standing reservation can be defined, a quality of service (QoS) should be created that will specify which users are allowed to submit jobs that will run in the new standing reservations.
QoS is a powerful concept in Moab, often used to control access to resources, instigate different billing rates, and control certain administrative privileges. Additional information on QoS and standing reservations is available.
Like the standing reservations, QoS is defined in the moab.cfg file. Example 16 shows how to create the four QoS options that are required to implement the standing reservations shown in Figure 3. This example assumes the noted users (admin, datacenter, web, apache and customer1) have been previously defined in the moab.cfg file.
Example 16: Sample QoS configuration
QOSCFG[nightly] QFLAGS=DEADLINE,TRIGGER QOSCFG[nightly] MEMBERULIST=admin,datacenter QOSCFG[daily] QFLAGS=DEADLINE,TRIGGER QOSCFG[daily] MEMBERULIST=admin,datacenter QOSCFG[web] MEMBERULIST=web,apache QOSCFG[contract1] QFLAGS=DEADLINE MEMBERULIST=customer1
Example 16 shows that four QoS options have been defined. The first and second QoS (nightly and daily) have special flags that allow the jobs to contain triggers and to have a hard deadline. All the QoS options contain a user list of those users who have access to submit to the QoS. Notice that multiple configuration lines are allowed for each QoS.
Once the QoS options have been created, the associated standing reservations must also be created. Example 17 shows how this is done in the moab.cfg file.
Example 17: Sample standing reservation configuration
SRCFG[dc_night] STARTTIME=00:00:00 ENDTIME=04:00:00 SRCFG[dc_night] HOSTLIST=Node0[1-8]$ QOSLIST=nightly SRCFG[dc_day] STARTTIME=06:00:00 ENDTIME=19:00:00 SRCFG[dc_day] HOSTLIST=Node0[1-5]$ QOSLIST=daily SRCFG[websrv1] STARTTIME=08:00:00 ENDTIME=16:59:59 SRCFG[websrv1] HOSTLIST=Node0[7-8]$ QOSLIST=web SRCFG[websrv2] STARTTIME=06:00:00 ENDTIME=19:00:00 SRCFG[websrv2] HOSTLIST=Node09 QOSLIST=web SRCFG[websrv3] STARTTIME=00:00:00 ENDTIME=23:59:59 SRCFH[websrv3] HOSTLIST=Node10 QOSLIST=web SRCFG[cust1] STARTTIME=17:00:00 ENDTIME=23:59:59 SRCFG[cust1] HOSTLIST=NODE0[6-8]$ QOSLIST=contract1
Example 17 shows the creation of the different standing reservations. Each of the standing reservations has a start and end time, as well as the host list and the associated QoS. Three separate standing reservations were used for the web services because of the different nodes and time period sets. This setup works fine here because Web services is going to be small, serial jobs. In other circumstances, a different reservation structure would be needed for maximum performance.
Q.3.4.3 Submitting a Job to a Standing Reservation
It is not uncommon for a particular user to have access to multiple QoS options. For instance, Example 16 shows the user datacenter has access to both the nightly and daily QoS options. Consequently, it is necessary to denote which QoS option is to be used when a job is submitted.
Example 18: Specifying a QoS option at job submission
> msub -l qos=nightly nightly.job.cmd
In Example 18, the script nightly.job.cmd is being submitted using the QoS option nightly. Consequently, it will be able to run using the nodes reserved for that QoS option in Example 17.
Q.3.5 Workflow Dependencies
With the different standing reservations and associated QoSs configured in Moab, the process of converting the workflow can continue. The next steps are to convert the compute jobs and build the dependency tree to support the workflow.
Q.3.5.1 Converting Compute Jobs
Most compute jobs will require few, if any, changes to run under the new paradigm. All jobs will be submitted to Moab running on the head node. (See Figure 2.) Moab will then schedule the job based on a number of criteria, including user, QoS, standing reservations, dependencies and other job requirements. While the scheduling is dynamic, proper use of QoS and other policies will ensure the desired execution of jobs on the cluster.
Jobs may read and write files from a network drive. In addition, Moab will return all information written to STDOUT and STDERR in files denoted by the Job ID to the user who submitted the job.
Example 19: Staging of STDERR and STDOUT
> echo env | msub 40278 > ls -l -rw------- 1 user1 user1 0 2007-04-03 13:28 STDIN.e40278 -rw------- 1 user1 user1 683 2007-04-03 13:28 STDIN.o40278
Example 19 shows the created output files. The user user1 submitted the env program to Moab, which will return the environment of the compute node on which it runs. As can be seen, two output files are created: STDIN.e40278 and STDIN.o40278 (representing the output on STDERR and STDOUT, respectively). The Job ID (40278) is used to denote which output files belong to which job. The first part of the file names, STDIN, is the name of the job script. In this case, because the job was submitted to msub's STDIN via a pipe, STDIN was used.
Q.3.5.2 Introduction to Triggers
Triggers are one way to handle dependencies in Moab. This section introduces triggers and several of their key concepts. Additional trigger information is available.
In its simplest form, a trigger has three basic parts:
- An object
- An event
- An action
The concept of resources in Moab has already been introduced. In addition to resources, Moab is aware of a number of other entities, including the scheduler, resource managers, nodes and jobs. Each of these are represented in Moab as an object. Triggers may be attached to any of these object types. Also an object instance can have multiple triggers attached to it.
In addition to an object, each trigger must have an event specified. This event determines when the trigger's action will take place. In Moab terminology, this is known as an event type. Some popular event types include cancel, create, end, start and threshold.
An action consists of two parts: (1) the action type and (2) the action command. The action type specifies what type of an action is to occur. Some examples include exec, internal and mail. The format of the action command is determined by the action type. For example, exec requires a command line, while mail needs an email address.
While triggers can be placed on any object type within Moab, the job object is the most useful for creating workflows. A trigger can be attached to an object at submission time through the use of msub and the -l flag.
Example 20: Submitting a job with a basic trigger from the command line
> msub -l trig=AType=exec\&EType=start\&Action="job_check.pl" Job.cmd
In Example 20, the job Job.cmd is submitted with one trigger. This trigger will execute the job_check.pl script when the compute job starts on the compute node. It is important to note that all triggers are run on the head node, even those attached to compute jobs.
Often, triggers are attached to special jobs known as system jobs. System jobs are simply an instantiation of a job object that does not require any resources by default. In addition, it also runs on the head node.
Example 21: Creating a system job with a trigger from the command line
> msub -l flags=NORESOURCES,trig=AType=exec\&EType=start\&Action="job_check.pl" Job
Just like normal jobs, system jobs can serve as a job group. In other words, when forming job groups, one is associating one job with another. The job to which all others attach is known as the job group, and its variable name space can be used as a common repository for each of the child jobs.
Example 22: Creating a job group and associating two jobs with the group
> echo true | msub -N MyJobGroup -l flags=NORESOURCES > msub -W x=JGroup:MyJobGroup Job1 > msub -W x=JGroup:MyJobGroup Job2
In Example 22, a system job is created and given the name MyJobGroup to simplify later use of the job group. Then two compute jobs, Job1 and Job2, are submitted. They are made part of the MyJobGroup job group, meaning they will have access to the variable name space of the first job.
As a security measure, only jobs submitted to QoS with the trigger flag can have triggers attached. An example of the configuration for this can be seen in Example 16.
Another important point with triggers is that they are event-driven. This means that they operate outside of the normal Moab batch scheduling process. During each scheduling iteration, Moab evaluates all triggers to see if their event has occurred and if all dependencies are fulfilled. If this is the case, the trigger is executed, regardless of the priority of the job to which it is attached. This provides the administrator with another degree of control over the system.
By combining compute jobs, system jobs, and triggers, one can build fairly complex workflows. The next few sections cover additional information on how to map the previously created workflow diagram to these concepts.
Q.3.5.3 Internal Dependencies
Internal dependencies are those that can be fulfilled by other jobs within the workflow. For example, if Job1 must complete before Job2, then Job1 is an internal dependency of Job2. Another possibility is that Job1 may also stage some data that Job3 requires, which is another type of internal dependency.
Internal dependencies are often handled through variables. Each trigger can see all the variables in the object to which it is attached. In the case of the object being a job, the trigger can also see the variables in any of the job's job group hierarchy. Triggers may require that certain variables simply exist or have a specific value in order to launch. Upon completion, triggers can set variables depending on the success or failure of the operation. In some instances, triggers are able to consume variables that already exist when they launch, removing them from the name space.
Figure 4: Jobs, job group and variables
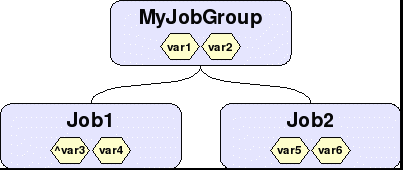
Figure 4 shows a simple setup where there is a job group (MyJobGroup) with two compute jobs associated with it (Job1 and Job2). In addition to their own variables, both Job1 and Job2 can see var1 and var2 because they are in MyJobGroup. However, Job1 cannot see var5 and var6, nor can Job2 see var3 and var4. Also, MyJobGroup cannot see var3, var4, var5 and var6. One can only see up the hierarchy tree.
Notice that var3 has a caret symbol (^) attached to the front. This means that when Job1 completes, var3 is going to be exported to the job group, MyJobGroup in this case. This can be seen in Figure 5, which shows the state of things after Job1 has completed.
Figure 5: Jobs, job group and variables after complete
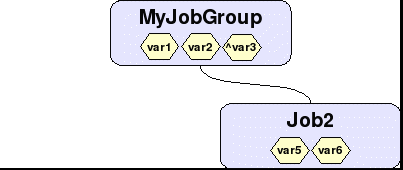
With the completion of Job1, var3 has been exported to MyJobGroup. However, var4, which was not set to export, has been destroyed. At this point, Job2 can now see var3. If a trigger attached to Job2 required var3, it would now be able to run because its dependency is now fulfilled.
This is a very simple example of how variables can be used in conjunction with triggers. Detailed information on the interaction between triggers and variables is available.
Q.3.5.4 External Dependencies
There are instances where dependencies must be fulfilled by entities external to the cluster. This may occur when external entities are staging in data from a remote source or when a job is waiting for the output of specialized test equipment. In instances such as these, Moab provides a method for injecting a variable into a job's name space from the command line. The mjobctl command is used.
Example 23: Injecting variables into objects from the command line
> mjobctl -m var=newvar1=1 MyJobGroup
In this example, the variable newvar1 with a value of 1 is injected into MyJobGroup, which was created in Example 22. This provides a simple method for allowing external entities to notify Moab when an external dependency has been fulfilled.
Q.3.5.5 Cascading Triggers
Another approach that can be used when converting a workflow is the idea of dynamic workflow. A dynamic workflow is one in which sections of the workflow are created on-the-fly through the use of triggers or other means. The technique of using triggers to accomplish this is known as cascading triggers. This is where triggers dynamically create other jobs and triggers, which handle parts of the overall work flow.
Cascading triggers reduces the number of triggers and jobs in the system, thereby reducing administrative overhead. While not the perfect solution in every case, they provide a great tool for those using Moab in the data center. See the Case Studies for an example of their benefits.
Q.4 Dynamic Workload
A dynamic workload is a non-static workload that changes over the course of a day, week, month or year. Moab supports this through the use of traditional HPC techniques. As jobs are submitted to Moab, they are evaluated for execution. This evaluation is based on a number of factors including policies, QoS, and standing reservations and assigns a priority to the job. These priorities are used when scheduling the job.
Where possible, Moab will backfill empty sections of the schedule with lower priority jobs if it will not affect the higher priority jobs. This scheduling occurs every scheduling iteration, allowing Moab to take advantage of changing situations. Because of the dynamic nature of Moab scheduling, it is able to handle the changing workload in a data center—providing services and resources for ad hoc jobs, as well as the normal, static workflow.
Q.5 Supporting SLAs and Other Commitments
When SLAs are in place, it is requisite that the workflow support these agreements. Contracted work must be accomplished accurately and on time. A number of Moab policies exist to ensure these goals can be met.
Moab has a number of different credential types which allow for the grouping of users in a large number of ways. Access rights can be given to each credential, and limits on system usage for each credential can be defined. Users are allowed to have multiple credentials, thereby providing a rich set of access control mechanisms to the administrator.
Moab's scheduling algorithms are customizable on a number of different levels, allowing administrators to determine when and where certain jobs are allowed to run. The dynamic nature of the scheduling engine allows Moab to react to changing circumstances.
Moab's scheduling engine takes multiple circumstances and priorities into consideration when ordering jobs. Because Moab considers the future when scheduling, jobs may be scheduled to start at or complete by specific times. In addition, resources can be statically or dynamically allocated for jobs submitted via certain credentials. Policies can be put in place to describe Moab behavior with jobs that are not abiding by the imposed restrictions.
In combination, all these features allow the administrator to customize Moab behavior to perfectly match their data center's needs.
Additional resources:
- Prioritizing Jobs and Allocating Resources
- Controlling Resource Access
- Managing Shared Resources
- Job Administration
- Node Administration
Q.CS Case Studies
This section illustrates Moab functionality in the data center. All company names presented in this section are fictitious.
Q.CS.1 Cascading Triggers
A data collection company handles a large amount of incoming information each day. New information is available every five minutes for processing. The information is processed by their cluster in a series of steps. Each step consolidates the information from the previous steps and then generates a report for the given time period, as shown in what follows:
- Every 5 Minutes – Information gathered and "5 Minute" report generated
- Every 15 Minutes – All new "5 Minute" data handled
- Every Hour – All new "15 Minute" data handled
- Every 3 Hours – All new "1 Hour" data handled
- Every Day – All new "3 Hour" data handled
The original approach was to create the entire workflow structure for the entire day with a standing trigger that fired every night at midnight. However, this produced a large number of triggers that made management of the system more difficult. For every "5 Minute" task requiring a trigger, 288 triggers are required. This quickly made the output of mdiag -T very difficult to parse for a human, as multiple tasks, and therefore triggers, were required for each step.
To address this issue, the cascading triggers approach was adopted. With this approach, triggers were only created as needed. For example, each "3 Hour" trigger created its underlying "1 Hour" triggers when it was its time to run.
The resulting reduction of triggers in the system was very impressive. Figure 6 shows the difference between the two approaches in the number of triggers when only one trigger is needed per step. The difference is even greater when more than one trigger is needed per step.
Figure 6: Cascading triggers comparison graphs
 |
| Click to enlarge |
The charts show the number of triggers over the full day that would be required if all jobs were generated at the beginning of the day versus a dynamic approach where jobs and their associated triggers were created only as needed. The difference in the two approaches is clear.