



5.2 Node Allocation Policies
While job prioritization allows a site to determine which job to run, node allocation policies allow a site to specify how available resources should be allocated to each job. The algorithm used is specified by the parameter NODEALLOCATIONPOLICY. There are multiple node allocation policies to choose from allowing selection based on reservation constraints, node configuration, resource usage, preferences, and other factors. You can specify these policies with a system-wide default value or on a per-job basis. Please note that LASTAVAILABLE is the default policy.
Available algorithms are described in detail in the following sections and include FIRSTAVAILABLE, LASTAVAILABLE, PRIORITY, CPULOAD, MINRESOURCE, CONTIGUOUS, MAXBALANCE, FASTEST, and LOCAL.
- 5.2.1 Node Allocation Overview
- 5.2.2 Resource Based Algorithms
- 5.2.3 Time Based Algorithms
- 5.2.4 Specifying Per Job Resource Preferences
5.2.1 Node Allocation Overview
Node allocation is the process of selecting the best resources to allocate to a job from a list of available resources. Making this decision intelligently is important in an environment that possesses one or more of the following attributes:
- heterogeneous resources (resources which vary from node to node in terms of quantity or quality)
- shared nodes (nodes may be utilized by more than one job)
- reservations or service guarantees
- non-flat network (a network in which a perceptible performance degradation may potentially exist depending on workload placement)
5.2.1.1 Heterogeneous Resources
Moab analyzes job processing requirements and assigns resources to maximize hardware utility.
For example, suppose two nodes are available in a system, A and B. Node A has 768 MB of RAM and node B has 512 MB. The next two jobs in the queue are X and Y. Job X requests 256 MB and job Y requests 640 MB. Job X is next in the queue and can fit on either node, but Moab recognizes that job Y (640 MB) can only fit on node A (768 MB). Instead of putting job X on node A and blocking job Y, Moab can put job X on node B and job Y on node A.
5.2.1.2 Shared Nodes
Symmetric Multiprocessing (SMP)
When sharing SMP-based compute resources amongst tasks from more than one job, resource contention and fragmentation issues arise. In SMP environments, the general goal is to deliver maximum system utilization for a combination of compute-intensive and memory-intensive jobs while preventing overcommitment of resources.
By default, most current systems do not do a good job of logically partitioning the resources (such as CPU, memory, and network bandwidth) available on a given node. Consequently contention often arises between tasks of independent jobs on the node. This can result in a slowdown for all jobs involved, which can have significant ramifications if large-way parallel jobs are involved. Virtualization, CPU sets, and other techniques are maturing quickly as methods to provide logical partitioning within shared resources.
On large-way SMP systems (> 32 processors/node), job packing can result in intra-node fragmentation. For example, take two nodes, A and B, each with 64 processors. Assume they are currently loaded with various jobs and A has 24 and B has 12 processors free. Two jobs are submitted; job X requests 10 processors and job Y requests 20 processors. Job X can start on either node but starting it on node A prevents job Y from running. An algorithm to handle intra-node fragmentation is straightforward for a single resource case, but the algorithm becomes more involved when jobs request a combination of processors, memory, and local disk. These workload factors should be considered when selecting a site's node allocation policy as well as identifying appropriate policies for handling resource utilization limit violations.
Interactive Nodes
In many cases, sites are interested in allowing multiple users to simultaneously use one or more nodes for interactive purposes. Workload is commonly not compute intensive consisting of intermittent tasks including coding, compiling, and testing. Because these jobs are highly variant in terms of resource usage over time, sites are able to pack a larger number of these jobs onto the same node. Consequently, a common practice is to restrict job scheduling based on utilized, rather than dedicated resources.
Interactive Node Example
The example configuration files that follow show one method by which node sharing can be accomplished within a TORQUE + Moab environment. This example is based on a hypothetical cluster composed of 4 nodes each with 4 cores. For the compute nodes, job tasks are limited to actual cores preventing overcommitment of resources. For the interactive nodes, up to 32 job tasks are allowed, but the node also stops allowing additional tasks if either memory is fully utilized or if the CPU load exceeds 4.0. Thus, Moab continues packing the interactive nodes with jobs until carrying capacity is reached.
# constrain interactive jobs to interactive nodes # constrain interactive jobs to 900 proc-seconds CLASSCFG[interactive] HOSTLIST=interactive01,interactive02 CLASSCFG[interactive] MAX.CPUTIME=900 RESOURCELIMITPOLICY CPUTIME:ALWAYS:CANCEL # base interactive node allocation on load and jobs NODEALLOCATIONPOLICY PRIORITY NODECFG[interactive01] PRIORITYF='-20*LOAD - JOBCOUNT' NODECFG[interactive02] PRIORITYF='-20*LOAD - JOBCOUNT'
interactive01 np=32 interactive02 np=32 compute01 np=4 compute02 np=4
# interactive01 $max_load 4.0
# interactive02 $max_load 4.0
5.2.1.3 Reservations or Service Guarantees
A reservation based system adds the time dimension into the node allocation decision. With reservations, node resources must be viewed in a type of two dimension node-time space. Allocating nodes to jobs fragments this node-time space and makes it more difficult to schedule jobs in the remaining, more constrained node-time slots. Allocation decisions should be made in such a way as to minimize this fragmentation and maximize the scheduler's ability to continue to start jobs in existing slots. The following figure shows that job A and job B are running. A reservation, X, is created some time in the future. Assume that job A is 2 hours long and job B is 3 hours long. Again, two new single-processor jobs are submitted, C and D; job C requires 3 hours of compute time while job D requires 5 hours. Either job will just fit in the free space located above job A or in the free space located below job B. If job C is placed above job A, job D, requiring 5 hours of time will be prevented from running by the presence of reservation X. However, if job C is placed below job B, job D can still start immediately above job A.
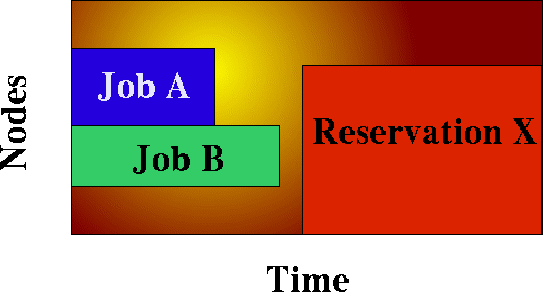
The preceding example demonstrates the importance of time based reservation information in making node allocation decisions, both at the time of starting jobs and at the time of creating reservations. The impact of time based issues grows significantly with the number of reservations in place on a given system. The LASTAVAILABLE algorithm works on this premise, locating resources that have the smallest space between the end of a job under consideration and the start of a future reservation.
5.2.1.4 Non-flat Network
On systems where network connections do not resemble a flat all-to-all topology, task placement may impact performance of communication intensive parallel jobs. If latencies and network bandwidth between any two nodes vary significantly, the node allocation algorithm should attempt to pack tasks of a given job as close to each other as possible to minimize impact of bandwidth differences.
5.2.2 Resource Based Algorithms
Moab contains a number of allocation algorithms that address some of the needs described earlier. You can also create allocation algorithms and interface them with the Moab scheduling system. The current suite of algorithms is described in what follows.
5.2.2.1 CPULOAD
Nodes are selected that have the maximum amount of available, unused CPU power (<#of CPU's> - <CPU load>). CPULOAD is a good algorithm for timesharing node systems and applies to jobs starting immediately. For the purpose of future reservations, the MINRESOURCE algorithm is used.
5.2.2.2 FIRSTAVAILABLE
Simple first come, first served algorithm where nodes are allocated in the order they are presented by the resource manager. This is a very simple, and very fast algorithm.
5.2.2.3 LASTAVAILABLE
This algorithm selects resources to minimize the amount of time after the job and before the trailing reservation. This algorithm is a best fit in time algorithm that minimizes the impact of reservation based node-time fragmentation. It is useful in systems where a large number of reservations (job, standing, or administrative) are in place.
5.2.2.4 PRIORITY
This algorithm allows a site to specify the priority of various static and dynamic aspects of compute nodes and allocate them with preference for higher priority nodes. It is highly flexible allowing node attribute and usage information to be combined with reservation affinity. Using node allocation priority, you can specify the following priority components:
The node allocation priority function can be specified on a node by node or cluster wide basis. In both cases, the recommended approach is to specify the PRIORITYF attribute with the NODECFG parameter. Some examples follow.
Example: Favor the fastest nodes with the most available memory that are running the fewest jobs.
NODEALLOCATIONPOLICY PRIORITY NODECFG[DEFAULT] PRIORITYF='SPEED + .01 * AMEM - 10 * JOBCOUNT' ...
 |
If spaces are placed within the priority function for readability, the priority function value must be quoted to allow proper parsing. |
Example: A site has a batch system consisting of two dedicated batchX nodes, as well as numerous desktop systems. The allocation function should favor batch nodes first, followed by desktop systems that are the least loaded and have received the least historical usage.
NODEALLOCATIONPOLICY PRIORITY NODECFG[DEFAULT] PRIORITYF='-LOAD - 5*USAGE' NODECFG[batch1] PRIORITY=1000 PRIORITYF='PRIORITY + APROCS' NODECFG[batch2] PRIORITY=1000 PRIORITYF='PRIORITY + APROCS' ...
Example: Pack tasks onto loaded nodes first.
NODEALLOCATIONPOLICY PRIORITY NODECFG[DEFAULT] PRIORITYF=JOBCOUNT ...
Example: Pack tasks onto nodes with the most processors available and the lowest CPU temperature.
RMCFG[torque] TYPE=pbs RMCFG[temp] TYPE=NATIVE CLUSTERQUERYURL=exec://$TOOLSDIR/hwmon.pl NODEALLOCATIONPOLICY PRIORITY NODECFG[DEFAULT] PRIORITYF='100*APROCS - GMETRIC[temp]' ...
Example: Send jobs with a certain size and application to nodes that have historically executed similar jobs in an efficient manner.
NODEALLOCATIONPOLICY PRIORITY NODECFG[DEFAULT] PRIORITYF='100*APPLAFFINITY' ...
5.2.2.5 MINRESOURCE
This algorithm prioritizes nodes according to the configured resources on each node. Those nodes with the fewest configured resources that still meet the job's resource constraints are selected.
5.2.2.6 CONTIGUOUS
This algorithm allocates nodes in contiguous (linear) blocks as required by the Compaq RMS system.
5.2.2.7 MAXBALANCE
This algorithm attempts to allocate the most balanced set of nodes possible to a job. In most cases, but not all, the metric for balance of the nodes is node procspeed. Thus, if possible, nodes with identical procspeeds are allocated to the job. If identical procspeed nodes cannot be found, the algorithm allocates the set of nodes with the minimum node procspeed span or range.
5.2.2.8 FASTEST
This algorithm selects nodes in the order of fastest node first order. Nodes are selected by node speed if specified. If node speed is not specified, nodes are selected by processor speed. If neither is specified, nodes are selected in a random order.
5.2.2.9 LOCAL
Calls the locally created contrib node allocation algorithm.
5.2.3 Time Based Algorithms
Time based algorithms allow the scheduler to optimize placement of jobs and reservations in time and are typically of greatest value in systems with the following criteria:
- large backlog
- large number of system or standing reservations
- heavy use of backfill
The FIRSTAVAILABLE, LASTAVAILABLE, and PRIORITY algorithms take into account a node's availability in time and should be considered in such cases.
5.2.4 Specifying Per Job Resource Preferences
While the resource based node allocation algorithms can make a good guess at what compute resources would best satisfy a job, sites often possess a subset of jobs that benefit from more explicit resource allocation specification. For example one job may perform best on a particular subset of nodes due to direct access to a tape drive, another may be very memory intensive. Resource preferences are distinct from node requirements. While the former describes what a job needs to run at all, the latter describes what the job needs to run well. In general, a scheduler must satisfy a job's node requirement specification and then satisfy the job's resource preferences as well as possible.
5.2.4.1 Specifying Resource Preferences
A number of resource managers natively support the concept of resource preferences (such as Loadleveler). When using these systems, the language specific preferences keywords may be used. For systems that do not support resource preferences natively, Moab provides a resource manager extension keyword, "PREF," which you can use to specify desired resources. This extension allows specification of node features, memory, swap, and disk space conditions that define whether the node is considered preferred.
|
Moab 5.2 (and earlier) only supports feature-based preferences. |
5.2.4.2 Selecting Preferred Resources
Enforcing resource preferences is not completely straightforward. A site may have a number of potentially conflicting requirements that the scheduler is asked to simultaneously satisfy. For example, a scheduler may be asked to maximize the proximity of the allocated nodes at the same time it is supposed to satisfy resource preferences and minimize node overcommitment. To allow site specific weighting of these varying requirements, Moab allows resource preferences to be enabled through the Priority node allocation algorithm. For example, to use resource preferences together with node load, the following configuration might be used:
NODEALLOCATIONPOLICY PRIORITY NODECFG[DEFAULT] PRIORITYF='5 * PREF - LOAD' ...
To request specific resource preferences, a user could then submit a job indicating those preferences. In the case of a PBS job, the following can be used:
> qsub -l nodes=4,walltime=1:00:00,pref=feature:fast
See Also
- Generic Metrics
- Per Job Node Allocation Policy Specification via Resource Manager Extensions